
Summary
As robots are deployed in increasingly diverse and dynamic environments, enabling them to adapt quickly remains a key challenge. One promising approach is to incorporate human interventions during deployment to guide learning. In this work, we propose a novel, fully differentiable model that captures how and when a human chooses to intervene. We use this model to train robot policies in a sample-efficient manner.
Imagine deploying a robot in a new environment. While it has been pre-trained in a factory, its performance is far from perfect when faced with real-world variability. Whether it’s a warehouse robot handling unexpected objects or a household assistant adapting to a cluttered kitchen, fine-tuning is often necessary to bridge the gap between training and deployment.
A natural way to fine-tune the robot’s behavior is through expert interventions—where a human monitors its actions and corrects mistakes as they occur. This interactive approach is both efficient and practical, since the interventions are easier to provide compared to full demonstrations. Not intervening also provides meaningful information about the optimality of the policy. And since interventions don’t require an expert to provide control signals at all times, they lower the bar for human oversight.
Existing intervention-based methods generally do not allow the human to intervene at will; instead, the robot queries the human based on predefined heuristics, or even when they do, these methods only utilize the data collected during intervention periods. But what about the intervals where we did not input any actions? Did we not provide any information to the robot? The answer is no: the fact that we chose not to intervene means the robot’s actions were already good enough in those intervals.
In our new work accepted at ICRA 2025, we propose a model to formulate how interventions occur in such cases, and show that it is possible to learn a policy with just a handful of expert interventions. Our key insight is that when an expert is able to intervene a system at will, how and when they intervene carry important information about the desired policy.
Intervention Model


To build our intervention model, let’s start with the following example: would you intervene with the robot’s operation when it is quickly moving toward a glass filled with water that stands on top of the countertop? Most people are likely to intervene in this case because they predict the robot may hit and knock over the glass, spilling water everywhere. This tells us that the humans’ belief about what the robot will do, i.e., their mental model of the robot, affects their decision to intervene.
Now, imagine the same situation, but the glass is empty. You’re less likely to intervene because even if the robot takes bad actions, the outcome is not going to be as bad as in the case of a full glass. So, the humans’ interventions also depend on how good/bad the potential outcomes are.
Considering these factors, we propose an intervention model that is based on the probit model from discrete decision theory. We start with modeling the probability that the human will intervene at a given state s, where ν is a binary random variable indicating the human intervention, and ah is the nominal human action, i.e., the action the human would take provided they decide to intervene.

The first term inside the summation is just the probability that the human would take action a at state s. Since we assume the human is a (noisy) expert, we use a Boltzmann policy under the true reward function of the environment to model this probability. The second term denotes the probability that the human will intervene, conditioned on the state and their nominal action. This is where we bring the probit model into play: the human will intervene only if their nominal action is considerably better than what they expect the robot to do.

Here, πˆ represents the mental model of the robot, i.e., what the human believes the robot will do in a given state, and we use Φ for the cdf of the standard normal distribution. In this probit-based model, the human is more likely to intervene if their intended action has significantly higher log-probability than the expected log-probability under the robot’s policy. The hyperparameter c reflects the effort required to intervene. If intervening is physically or cognitively demanding, c is high, and the human will only intervene if the difference in log probabilities is extremely high.
So, in a way, we formulate the intervention problem as a preference problem where the human intervenes if they prefer their policy over the robot’s policy.
Once we model the probability of human intervention, we can also express how the human acts when they do intervene using marginalization and conditional probability. Importantly, the final human action is defined to be equal to the nominal human action only in the case of intervention; otherwise, it remains undefined, since the human does not provide an action when they choose not to intervene.

Learning from Interventions
The robot misses information about two critical components in the intervention model: the model of what the human thinks the robot will do, πˆ, and the human’s policy, πh. In our learning algorithm, we model both of these policies with neural networks, πˆξ and πθ, respectively, and estimate the intervention probability and intervention action using our intervention model. Since this model is differentiable, we conveniently utilize the gradients coming from it to jointly train these networks using the collected dataset. During inference time, we only employ the trained policy πθ and discard the mental model.

We consider an initial policy in the environment. A human operator oversees the agent during task execution and may decide to take over control at any timestep. The human makes the decision to intervene based on their prediction of the robot’s potential failure, without observing the robot’s action in that state. If they think the robot will fail, they take over the controls. During the data collection phase, all interactions with the environment are recorded, both with and without interventions. The policy is then trained on this dataset using an iterative process that uses our intervention model.

Experiments and Results
We tested our method on four different simulation tasks, one with a discrete and three with continuous action spaces. To evaluate our approach, we compare it against several imitation learning and reinforcement learning (RL) methods that utilize interventions.
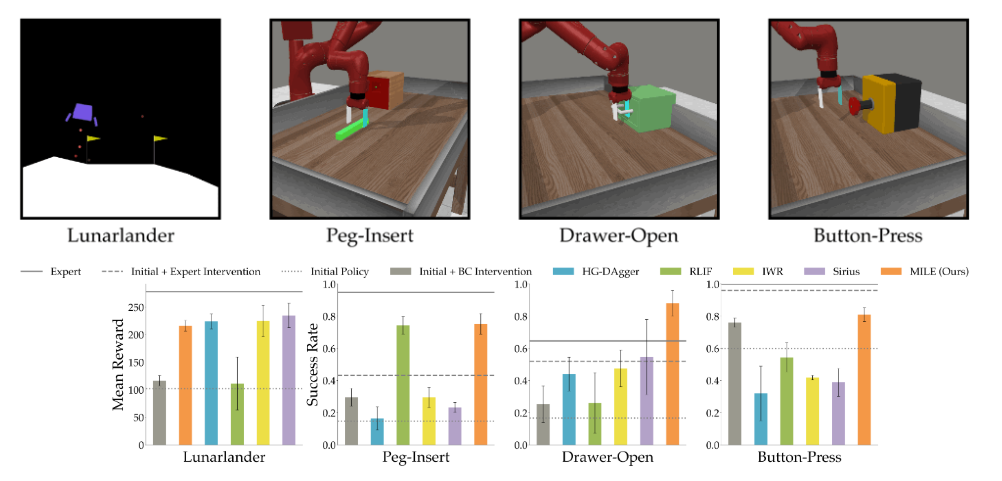
We observe that MILE achieves the best results across all environments, showing its sample efficiency. Due to the small amount of data, which mostly consists of states with no interventions, imitation learning methods suffer from overfitting as well as compounding errors. On the other hand, the RL-based method fails to produce stable results in most environments, possibly due to there being too few samples to learn a successful policy.
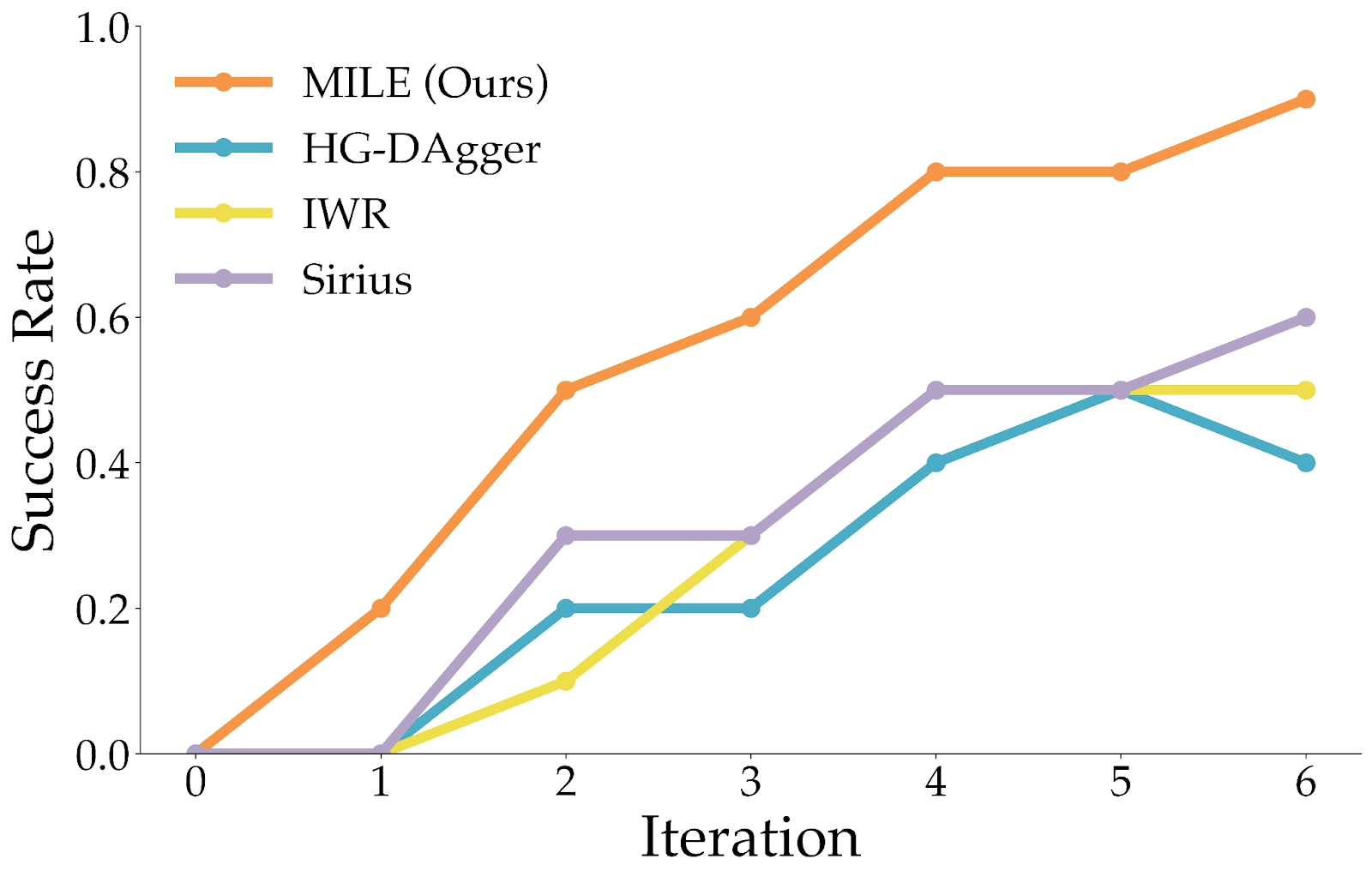
We also evaluated the performance of our method in a real-world setting where the task is to put an octagonal block into a wooden box through the correct hole. The robot begins with a mediocre policy that cannot complete the task on its own. During execution, a human can take control of the robot at any time to provide corrections. As in our simulation experiments, we assume no access to offline expert demonstrations—we rely solely on intervention trajectories. Our method is able to achieve 80% success rate just after 4 iterations, while other baselines struggle to improve the policy.
Finally, we conducted a user study to analyze how accurately our model estimates the humans’ interventions, as the success of our method relies on the success of the intervention model capturing when and how humans intervene the robot. We recruited 10 participants and used the same task setting and experiment setup as the experiment with the physical robot.
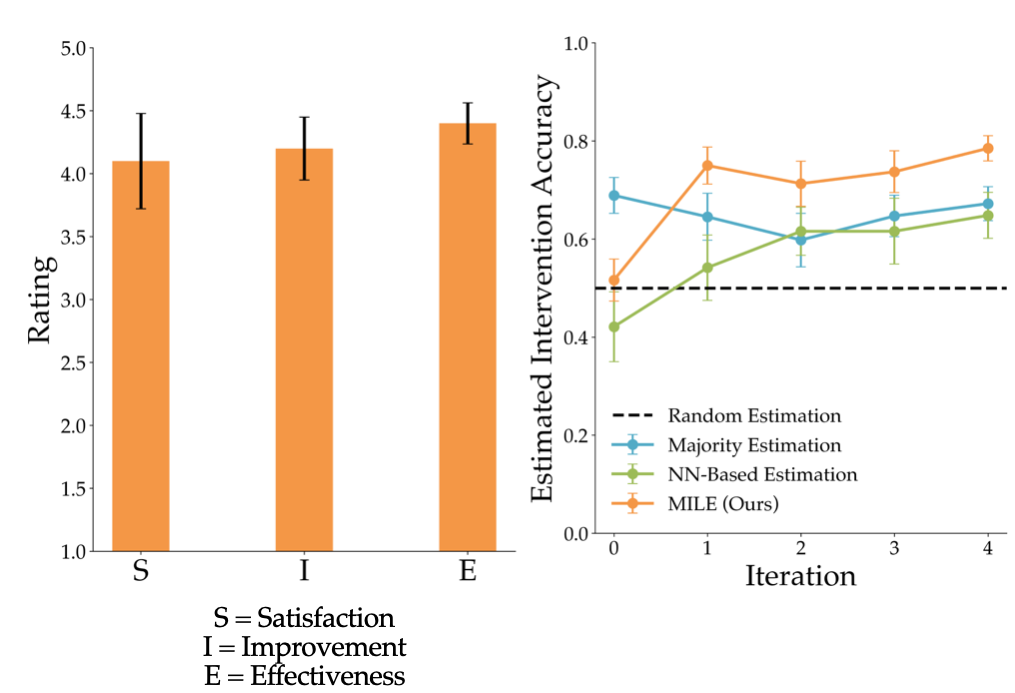
We compared our intervention model with the majority estimator that always predicts no intervention (the intervention rate of humans is around 30-40% throughout the procedure) and a neural network based estimator trained with the data from previous iterations to classify interventions in the current iteration. Our model outperforms both methods in predicting when an intervention will occur.
In this work, we presented MILE, a novel way of integrating interventions in policy learning. We developed a fully differentiable intervention model to estimate when and how the interventions occur, and a policy training framework that uses the intervention model. For future work, an exciting direction is extending this approach to learn from language-based corrections, which could naturally complement our intervention model and further enrich human-robot interaction.
For more information, please visit our website: https://liralab.usc.edu/mile/. We will be presenting MILE at the International Conference on Robotics and Automation (ICRA) 2025.