
Summary
Learning robot policies from image-based observations is a challenging task. We introduce a simple, yet effective framework for leveraging human domain knowledge in the form of human saliency maps to assist robots in solving visual control tasks.
Teaching robots to perform complex control tasks from high-dimensional image inputs is a nontrivial problem. State-of-the-art methods require hundreds of manually collected expert demonstrations or hours to days of training in simulation to learn a simple pick-and-place skill. One reason for this is that images are cluttered with distractions for robots, such as background objects and varying lighting conditions, making it difficult for them to extract useful features for decision-making. They must learn to effectively compress pixel data into a lower-dimensional representation.
Studies in neuroscience found that humans utilize selective attention to focus on task-relevant information for efficiently processing complex visual scenes. When performing everyday pick-and-place tasks, we employ selective attention to identify the target objects, focus on the grasp points, and execute precise hand-eye coordination. Drawing inspiration from our visual mechanisms, we developed a method to learn visual representations that capture useful features of the sensory input to simplify the decision-making process. While prior works proposed to learn such representations through various self-supervised objectives, such as contrastive learning, and data augmentation, we focus on saliency, a continuous heatmap that represents the importance of different parts of an image that are often tracked by our gaze patterns. Saliency introduces additional human domain knowledge to inform the representation of task-relevant features in the visual input and filters out uninformative perceptual noise.

Figure 1: ViSaRL consists of three steps: training a saliency predictor to annotate saliency maps, training a visual encoder with saliency labels, and finally using the image representations to learn an RL policy.
Visual Saliency-Guided Reinforcement Learning
We introduced Visual Saliency Reinforcement Learning (ViSaRL), a general approach for incorporating human saliency maps as an inductive bias to improve visual representations. ViSaRL can be implemented on top of any standard reinforcement learning algorithm for learning a policy. It aims to learn representations that encode useful task-specific inductive biases from human saliency maps.
ViSaRL consists of three learned components: a saliency predictor, an image encoder, and a policy network. Given an input RGB image observation, a saliency predictor first maps an input image to a continuous map highlighting important parts of the image for the downstream task. Our method is agnostic to the choice of saliency model. In this work, we use Pixel-wise Contextual Attention network (PiCANet).
Pretraining Multimodal Visual Representation
We use our trained saliency predictor to pseudo-label an offline image dataset collected using any behavior policy (random, replay buffer, expert demonstrations, etc.) with saliency maps. We then use the paired image and saliency dataset to pretrain an image encoder . We experiment with two models for our backbone visual encoder, CNN and Transformer, and investigate different techniques for augmenting each with saliency input. To add saliency to a CNN, we can use saliency as a continuous mask or simply add it as an additional channel per pixel. For a Transformer encoder, we pretrain the model with saliency as an additional input using a masked reconstruction objective.
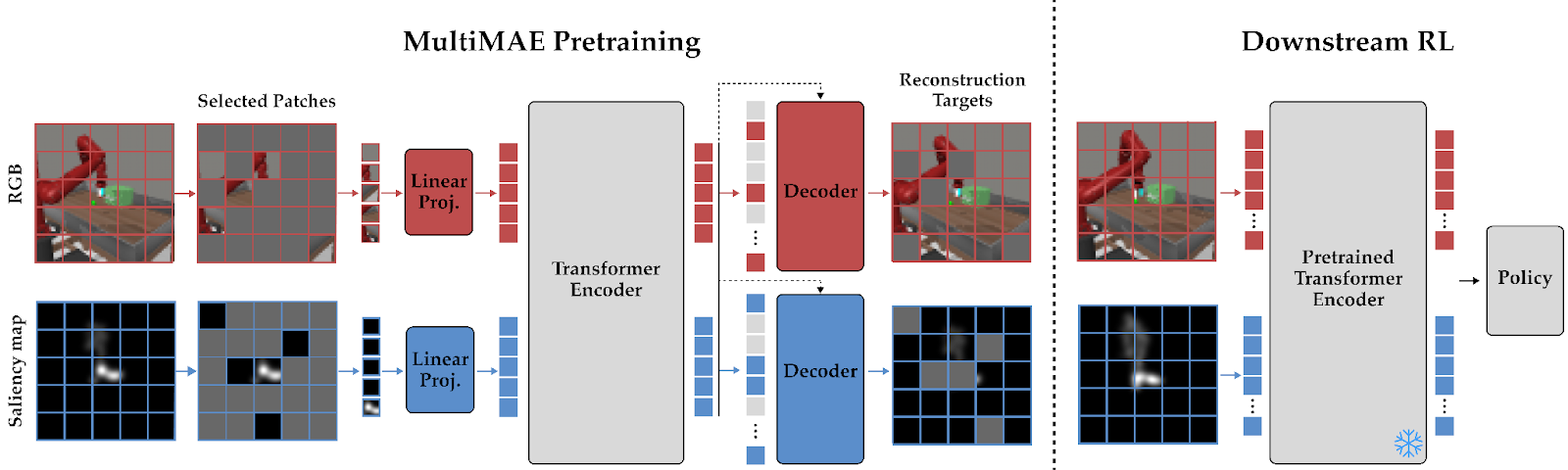
Figure 2: We use the MultiMAE architecture which employs a self-supervised masked-reconstruction objective to learn multimodal representations of RGB images and saliency maps.
The standard MAE architecture is limited to processing just RGB images. We propose to incorporate saliency using the MultiMAE architecture shown in Figure 2. MultiMAE extends MAE to encode multiple input modalities in a way that these modalities are contributing synergistically to the resulting representation. A cross attention layer is used in each decoder to incorporate information from the encoded tokens of other modalities. Crucially, MultiMAE’s pretraining objective requires the model to perform well in both the original MAE objective of RGB in-painting and cross-modal reconstruction, resulting in a stronger cross-modal visual representation. After pretraining the MultiMAE model, we freeze the encoder and use it to compute latent representations of environment observations for policy training.
ViSaRL is not only compatible with online RL algorithms such as Soft-Actor Critic (SAC) in which the agent learns through environment interactions but also imitation learning from expert demonstrations. The full procedure for ViSaRL is summarized in Algorithm 1.

Experiments and Results
ViSaRL achieves an 18% improvement in task success rate in MetaWorld compared to state-of-the-art baselines and nearly doubles the task success rate in real-robot experiments! ViSaRL is also robust to various visual perturbations, such as different backgrounds, distractor objects, and cluttered tabletops. We evaluate the generalizability of our learned representations on the challenging random colors and video backgrounds benchmark from DMControl-GB and find that ViSaRL significantly outperforms the baselines across all tasks with an average 19% and 35% relative improvement respectively for the color and video settings.
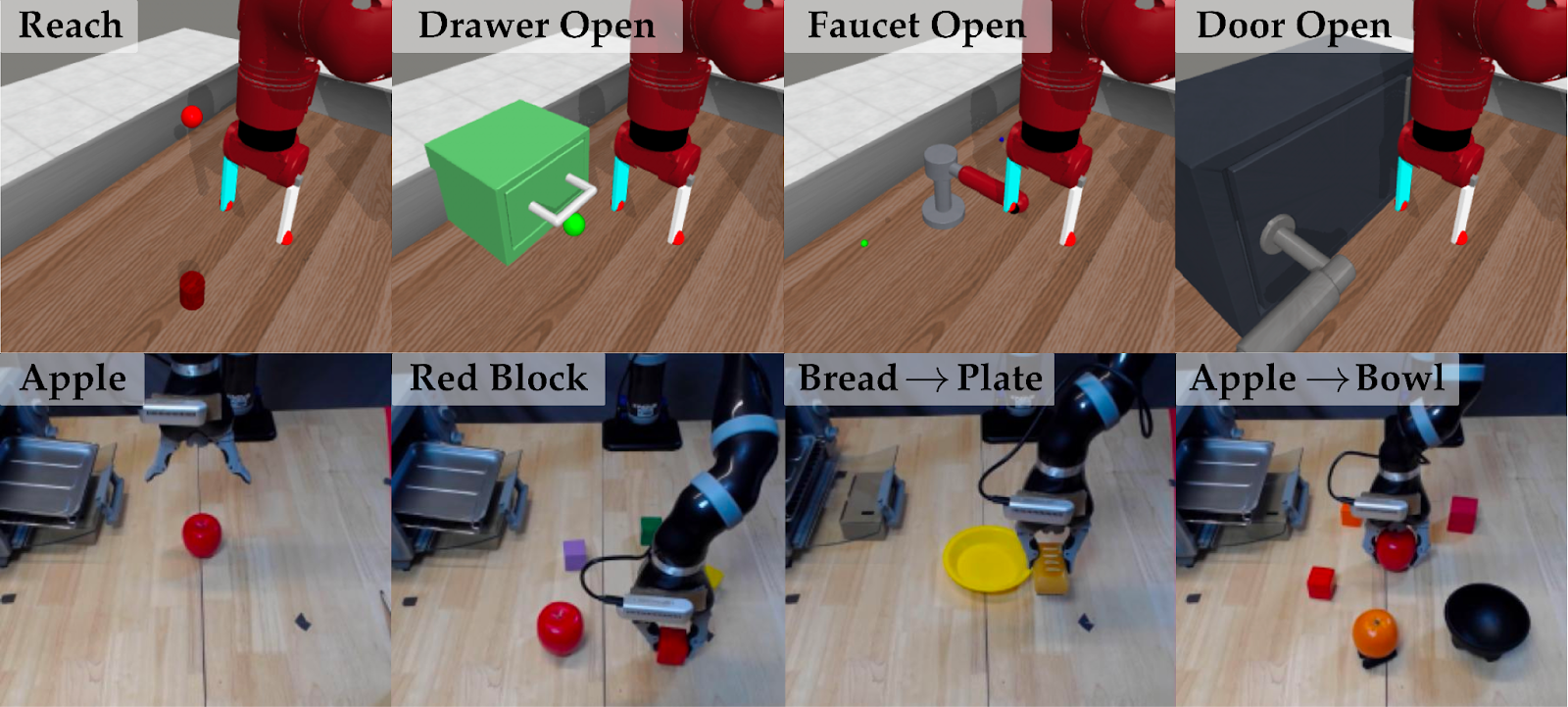
Figure 3: Evaluation tasks in MetaWorld simulation and with real world Jaco robot arm.
Human-annotated saliency improves performance compared to depth and surface normals. We conduct ablation experiments to compare saliency versus other mid-level input modalities such as depth and surface normals proposed by Sax et al. We substitute saliency with these other modalities as input to the MultiMAE. We observe that neither depth nor surface normal features alone improves task success over just using RGB image input. By contrast, adding saliency as an additional modality consistently improves task success suggesting that human-annotated saliency information helps learn better visual representations compared to other input modalities.


Figure 4: Evaluation rollout without saliency (left) and with saliency-based representations (right)
Overall, we demonstrate that using ViSaRL to incorporate information from human saliency into a learned visual representation greatly improves performance and robustness of visual control policies.
In the future, we are excited to explore the use of natural human gaze collected from a gaze tracker. We are also interested in leveraging temporal information from gaze movement to better understand and reason about a human’s intentions. Finally, we are interested in investigating the use of gaze for disambiguating user intent and tackling the problem of causal confusion.
For more information, please visit our website: https://liralab.usc.edu/visarl/. We will be presenting ViSaRL at the International Conference on Intelligent Robots and Systems (IROS) 2024.